

dg5R
Datacenter in a Box
Overview
Independent AI Infrastructure Managing 10kW Ultra-High Heat
dg5R is equipped with the most advanced deepgadget liquid cooling technology, enabling up to 10 AI chips to operate at room temperature. With comprehensive cooling covering CPU, memory, and NICs, performance is pushed to its limits, while the latest architecture support and remote monitoring maximize operational convenience. dg5R is the most practical AI infrastructure available now, from challenging server rooms to small and large data centers.
Recommended Workloads
What You Can Do Right Now with dg5R

AI Inference

LLM Tuning

Industrial & Financial High-Performance Computing

Image Workflows
Highlights
AI Power in a Single Server
Max AI Processors
LLM Inference
LLM Training
High-Speed Network
dg5R features a total of 15 PCIe 5.0 x16 slots, with up to 10 available for AI processor expansion. LLM inference theoretical peak is 33.4 PFLOPS with 10 NVIDIA H200 NVL GPUs under FP8 Tensor and Structured Sparsity conditions; LLM training theoretical peak is 8.3 PFLOPS under BF16 Dense with the same configuration. For networking, multiple 400Gbps+ InfiniBand / RoCE NICs can be installed, supporting both InfiniBand and Ethernet protocols.
Energy Efficiency
~30% improvement vs. air-cooled 1.85
Air-Cooled vs. dg5R vs. dg5R + Dry Cooling + Free Cooling
| Air-Cooled | dg5R | dg5R + Dry Cooling + Free Cooling | |
|---|---|---|---|
| IT Power | 672.0 kW | 672.0 kW | 672.0 kW |
| Server Cooling | 300.0 kW | 132.8 kW | 132.8 kW |
| Central HVAC | 224.0 kW | 96.0 kW | 27.9 kW |
| UPS Loss | 33.6 kW | 33.6 kW | 33.6 kW |
| Other | 15.0 kW | 10.0 kW | 10.0 kW |
| Total Power | 1,244.6 kW | 944.4 kW | 876.3 kW |
| PUE | 1.85 | 1.41 | 1.30 |
* Based on 100-server datacenter (IT power 672 kW), same workload. Air-cooled servers require ~20°C intake for stable operation; figures calculated under that condition. dg5R (self-contained L2A) figures calculated at 35°C intake.
Supports Up to 10 Latest AI Accelerators
Supports up to 10 of the latest NVIDIA GPUs as well as a wide range of next-generation AI accelerators from AMD, Tenstorrent, FuriosaAI, and more. Configure the perfect environment for your workloads.

High-Performance Enterprise
NVIDIA H200 NVL

Large-Scale Inference
NVIDIA RTX PRO 6000

Best Value
NVIDIA RTX 5090
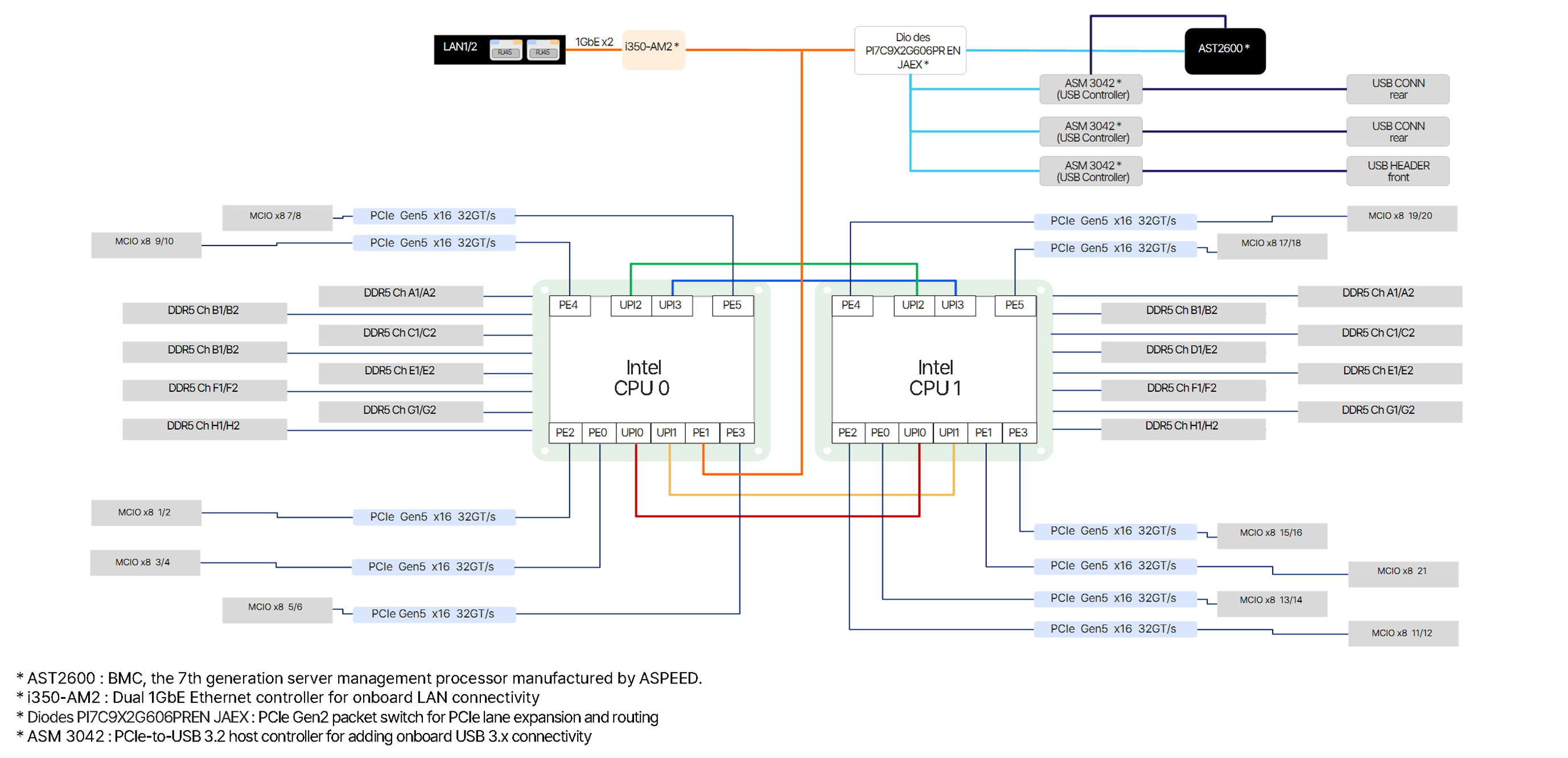
Mainboard
Intel · AMD Dual Platform Support
Technology
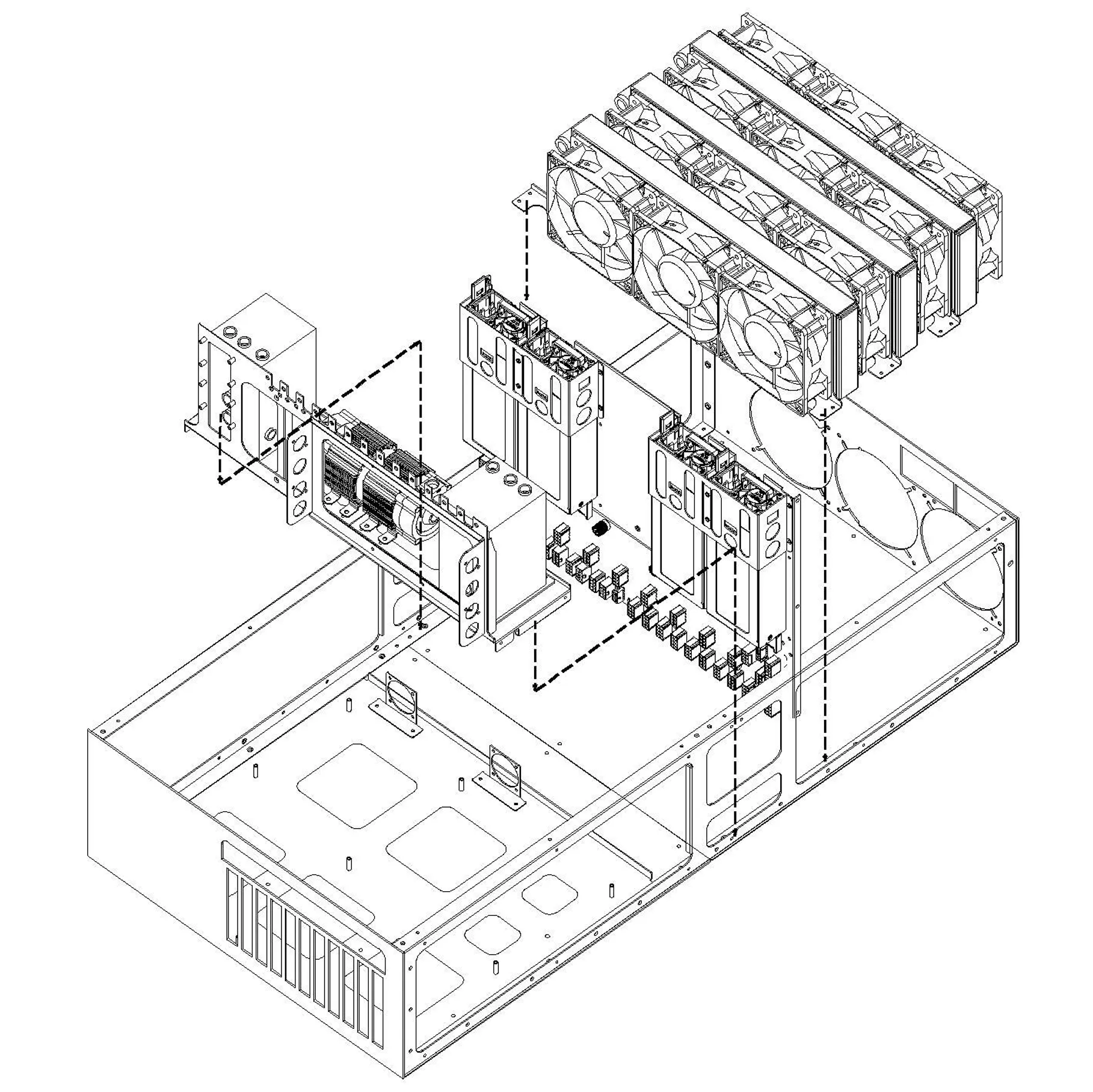
More Thorough and Reliable deepgadget Liquid Cooling
Scientific L2A (AALC) Cooling Flow with CFD Analysis
AALC(Air-Assisted Liquid Cooling) is a structure where liquid captures heat and air manages final heat rejection. Cold plates in direct contact with major heat sources such as CPUs, AI processors, and NICs absorb heat into the coolant, which then passes through built-in radiators to release that heat into the air. The discharged heat is handled by the data center’s existing HVAC system, allowing flexible deployment within conventional air-cooled infrastructure without direct facility water connections. The entire cooling path is optimized through CFD-based design to deliver high cooling efficiency and stable operation.

Liquid Cooling for AI Chips, CPU, NIC, and Memory
Liquid cooling is applied to all heat-generating components including NIC, chipset, and CPU, Memory not just GPUs. Efficiently manages heat across the entire system to maintain optimal performance.

Patented StackFlow Technology
deepgadget's patented StackFlow technology achieves maximum heat dissipation efficiency in limited space. Stacked radiator structure, flow path design, and parallel cooling flow enable stable temperature management.
• Cooling System for Server — Patent No. 10-2879706
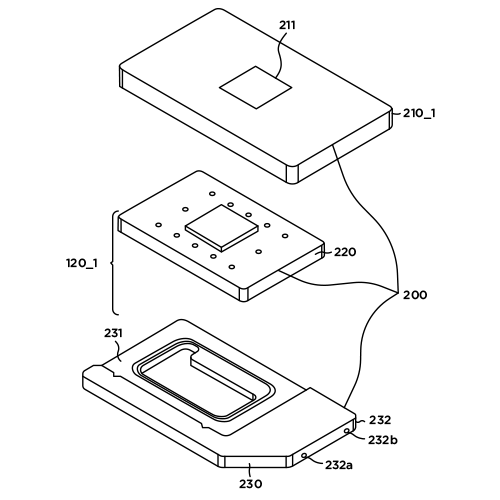
In-house Cooling Plate Design Capability
We design cooling plates optimized for each chip including GPU, CPU, and NIC to maximize heat transfer efficiency. Patented design ensures uniform cooling performance.
• Water Cooling Device for Computer and Driving Method — Patent No. 10-2118786
Powerful Flow Rate from 4 Pumps
Four pumps — two per loop — continuously push coolant through two independent cooling circuits. With up to 16 liters per minute circulating at full force, heat from AI processors and CPUs is absorbed and carried away the instant it's generated. And if one loop encounters an issue, the other keeps cooling without interruption, so the server never has to throttle down.

Certified Quality & Trust
Verified by domestic and international certification bodies — ISO 9001 quality management, direct in-house production, and venture company recognition for technology and growth potential.

Quality Management
ISO 9001

Ministry of SMEs
Direct Production Cert.

Ministry of SMEs
Venture Company Cert.
Configuration
Latest Architecture for Large-Scale Workloads
Latest AI Processor Support
- NVIDIAPRO 6000 Blackwell · H200 NVL · RTX 5090
- AMDRX 9070 XT · AI PRO R9700
- TenstorrentBlackhole p150a · Wormhole n300s
- FuriosaAIRNGD · WARBOY
Latest CPU Support (Dual)
- Intel Xeon 6700 Series
- Intel Xeon 6900 Series
- AMD EPYC 9005 Series
- Dual CPU Configuration Support
PCIe Gen 5 Slots
- Up to 15 PCIe 5.0 x16 Slots
- Up to 128 GB/s bidirectional bandwidth per slot
DDR5-6400 Memory Support
- ECC RDIMM Support
- Intel Xeon 6700 SeriesUp to 32 DIMMs (4TB)
- Intel Xeon 6900 Series/AMD EPYC 9005 SeriesUp to 24 DIMMs (3TB)
High-Speed NIC Support
- NVIDIA ConnectX-7 NDR / 400GbE
- NVIDIA ConnectX-6 HDR / 200GbE
- InfiniBand / Ethernet Dual-Mode
- RDMA, RoCEv2 Support
1GbE & IPMI Support
Comes standard with 2 x 1GbE Base-T ports and IPMI remote management. Monitor and manage your server reliably from anywhere.
Expandable Storage
Supports M.2 NVMe SSD (HW RAID) and up to 16 U.2 NVMe SSDs. Capacities range from 3.84TB to 61.44TB per drive; with 61.44TB drives, total storage reaches up to 983TB.
Enterprise 3200W Hot-Swap Redundant PSU
Equipped with four 3,200W 80 Plus Titanium certified PSUs. Supports both hot-swap and redundancy for stable power delivery during live server operation.
dg5R Supported AI Processor Performance Comparison
Select an AI Processor supported by dg5R to compare its performance against competing products. Highlighted items are models supported by dg5R.
* Performance figures are based on manufacturer-disclosed specifications; some are estimated. Actual performance may vary depending on system configuration and environment.
Support
Convenient Monitoring, Proactive All-in-One Management.
Dashboard
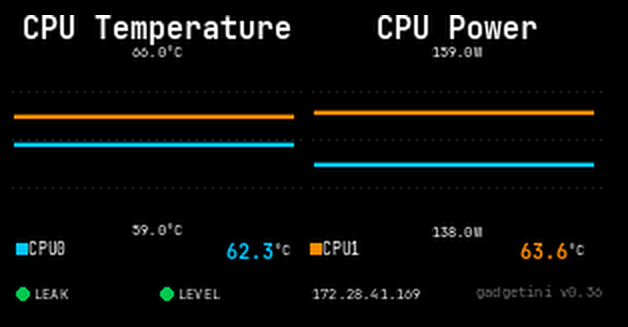
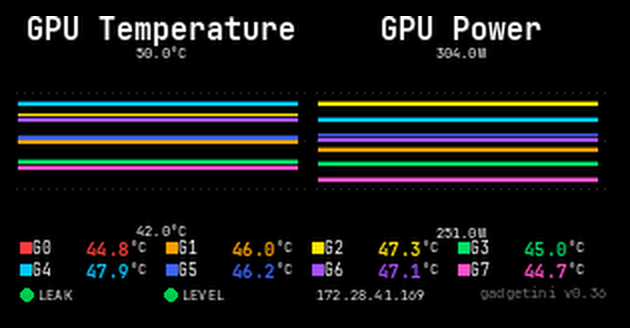
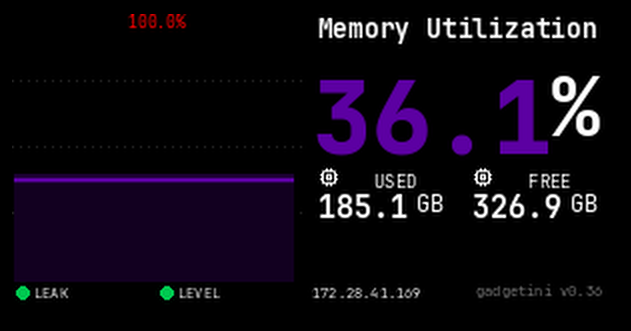
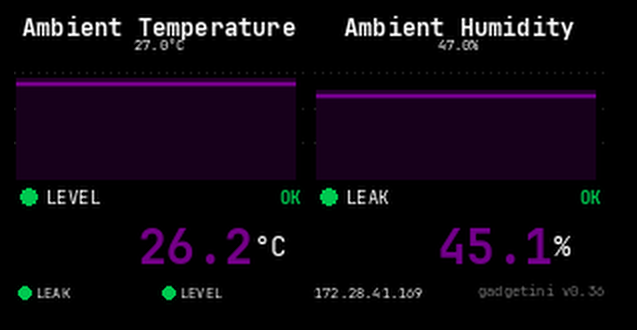
gadgetini, our web-based monitoring software, covers the entire server across six dedicated panels: Overview, Cooling Health, Compute Health, Network Health, History, and Alerting. Color-coded Normal / Warning / Critical status gives you an instant read on server health, while real-time data spans per-loop coolant temperature, leakage, and level — alongside AI processor and CPU temperature, power, and utilization — plus NIC link status and InfiniBand chipset temps. A 24-hour history graph lets you trace anomalies back to their source, and threshold breaches trigger instant email and Slack alerts. Accessible from desktop or mobile, anywhere.
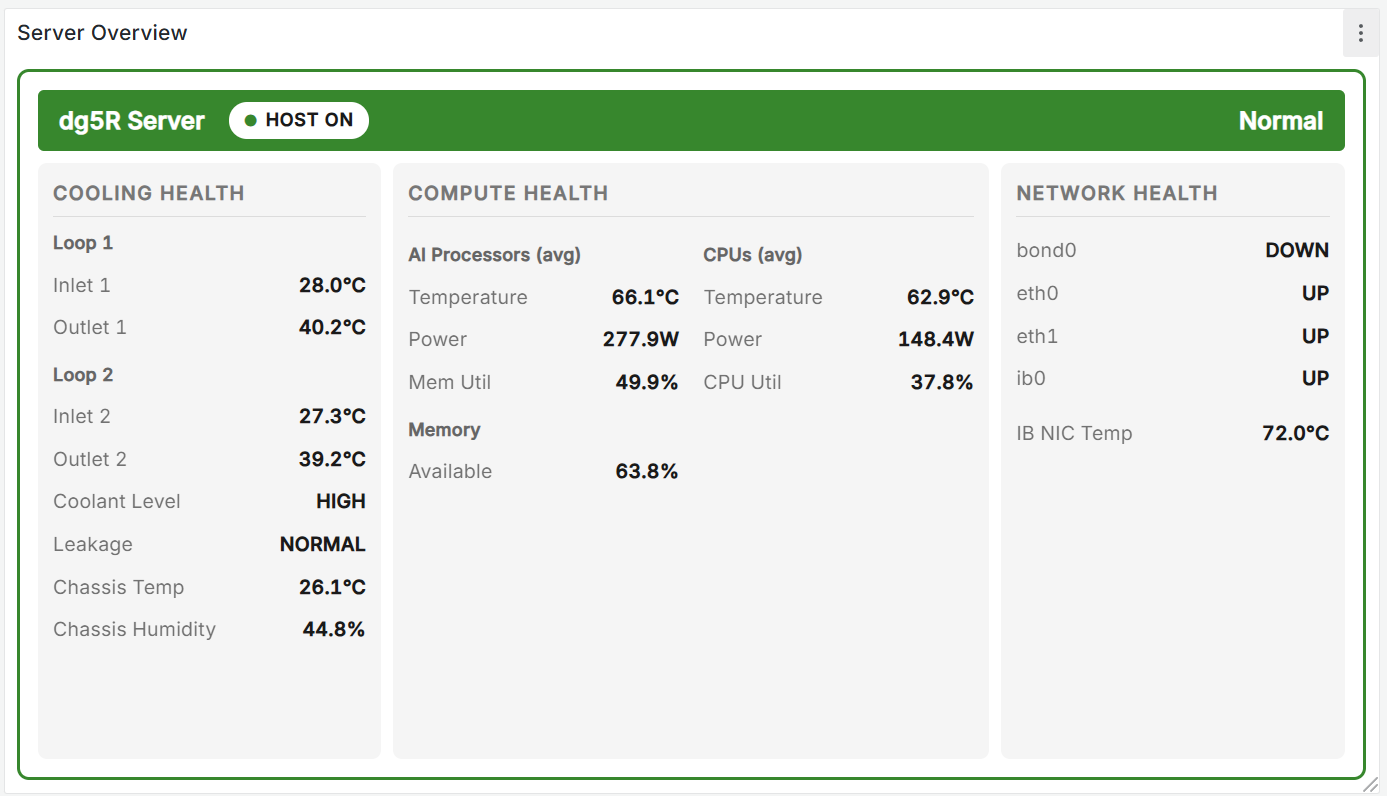
Overview
Server status is color-coded Normal / Warning / Critical at a glance. Cooling (Inlet/Outlet/ΔT, leakage, level), AI processors, CPUs, and network link status are all summarized on one panel.
Display
The built-in front LCD display lets you check server status directly. It shows all information available on the dashboard, and display modes can be freely selected via the gadgetini web UI.
Instant deep learning.
Preloaded for AI. Ready to train from day one.
deep gadget comes preloaded with all the software needed for AI research and development—so you can start deep learning the moment you power it on. From the OS to the deep learning stack, everything is optimized by the deep gadget team. Designed for effortless compatibility, so you can stay focused on your research.
OS
- Ubuntu
- RHEL
- Rocky Linux
- Windows
Drivers
- NVIDIA
- AMD
- Tenstorrent
- Infiniband/GbE
Runtime & Libraries
- CUDA
- cuDNN
- NCCL
- cuBLAS
- TensorRT
- ROCM
Deep Learning Frameworks & Solutions
- PyTorch
- TensorFlow
- DeepSpeed
- Ollama
- Horovod
- vLLM
- 3rd Party Solutions
Development Tools
- MPI
- Anaconda
- Docker
Specifications
dg5R Specifications
447mm x 911.5mm x 311mm(7U) when NVIDIA RTX 5090 is installed
6725P · 6737P · 6747P · 6767P · 6756E · 6780E
Intel Xeon 6900 Series — Dual, up to 128 Cores/CPU
6952P · 6972P · 6960P · 6978P · 6980P
AMD EPYC 9005 Series — Dual, up to 128 Cores/CPU
9135 · 9355 · 9455 · 9555 · 9755
NVIDIA RTX PRO 6000 Blackwell Server Edition
NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition
NVIDIA H200 NVL Tensor Core
NVIDIA RTX 5090
AMD RX 9070 XT · AMD AI PRO R9700
tenstorrent Wormhole n300s · tenstorrent Blackhole p150a
FuriosaAI RNGD · FuriosaAI WARBOY
Intel 6700: up to 4,096 GB (32 × 128 GB)
Intel 6900 · AMD: up to 3,072 GB (24 × 128 GB)
Up to 16× U.2 NVMe SSD (up to 983 TB)
Up to 16× 2.5" SATA SSD (up to 128 TB) RAID Controller included
NVIDIA ConnectX-6 — InfiniBand EDR / HDR200 / Ethernet 200GbE
NVIDIA ConnectX-7 — InfiniBand NDR / Ethernet 400GbE


